Model Architecture
Generator Network
- Encoder: 7-stage downsampling with residual blocks
- Decoder: 7-stage upsampling with skip connections
- Latent Space: 256-dimensional VAE
- Activation: LeakyReLU (α=0.2)
- Normalization: Group Normalization
- Output: Sigmoid activation for 256x256x3 images
Discriminator Network
- Type: Multi-scale PatchGAN
- Scales: 4 levels of feature discrimination
- Activation: LeakyReLU (α=0.2)
- Output: Real/Fake classification at multiple scales
Loss Functions
Generator Loss
- Adversarial Loss: LSGAN (Least Squares GAN)
- Cycle Consistency Loss: L1 norm (λ=10)
- KL Divergence: Regularization for latent space (λ=0.5)
Discriminator Loss
- Real/Fake Loss: LSGAN (Least Squares GAN)
- Multi-scale Loss: Aggregated across 4 scales
Training Progress
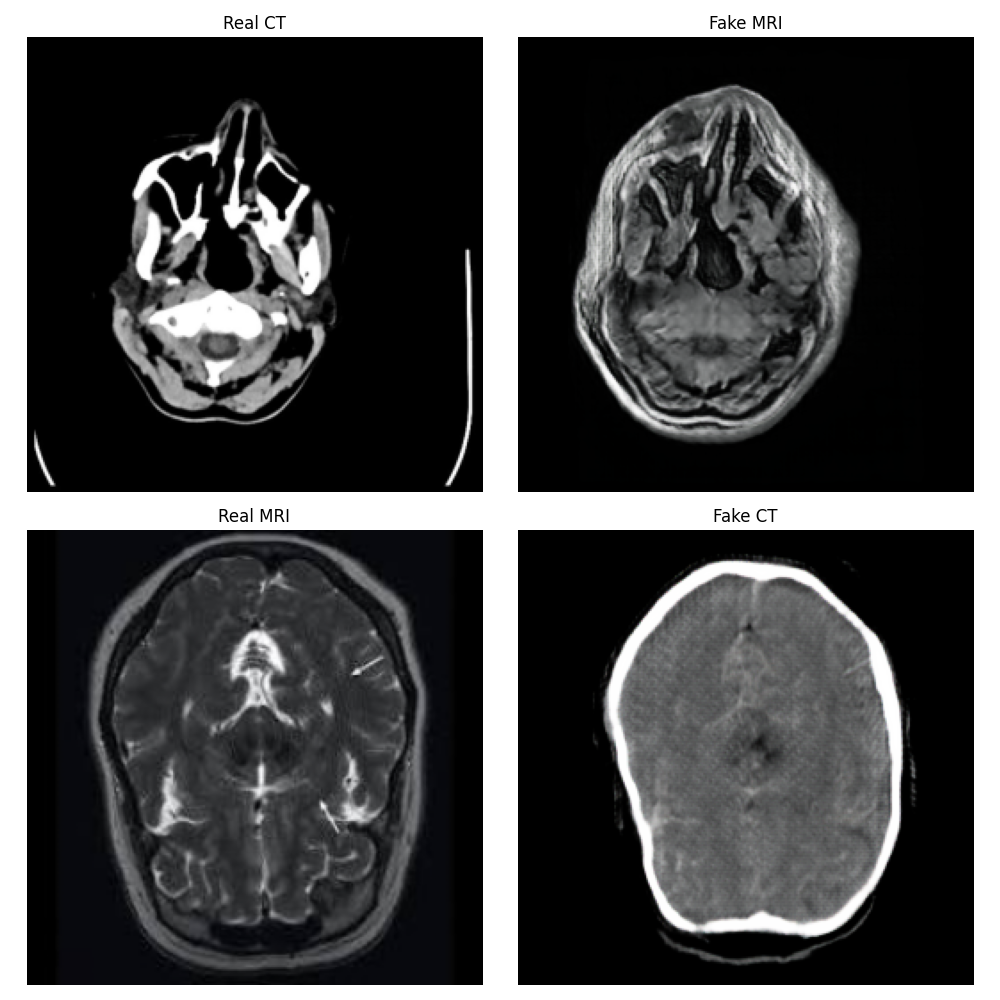
Epoch 1
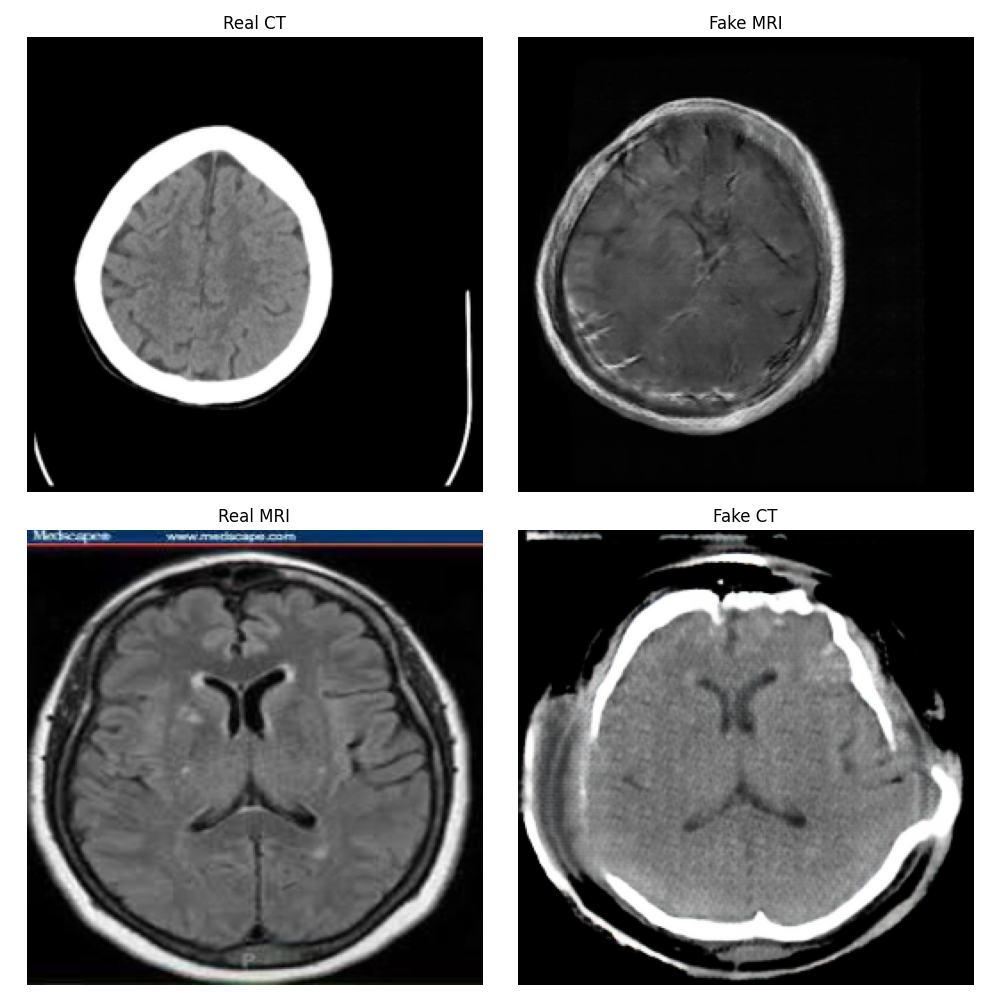
Epoch 2
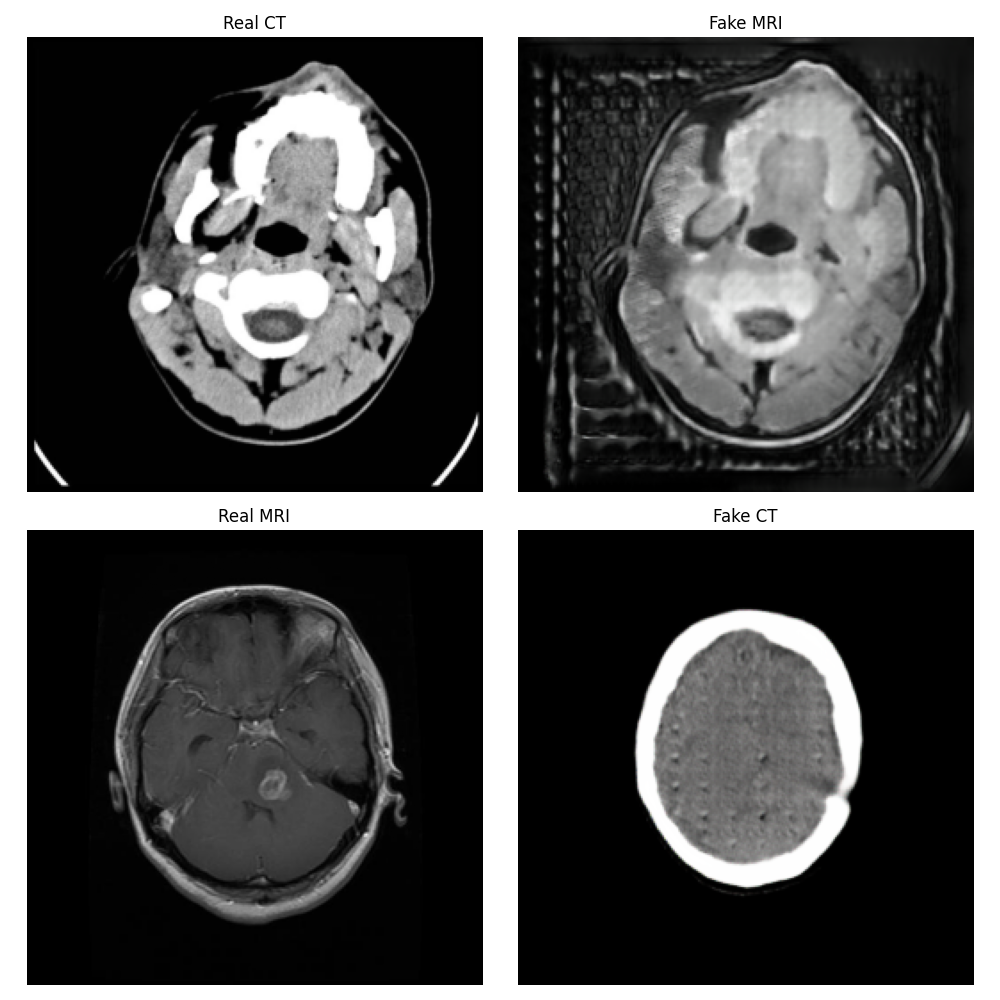
Epoch 3
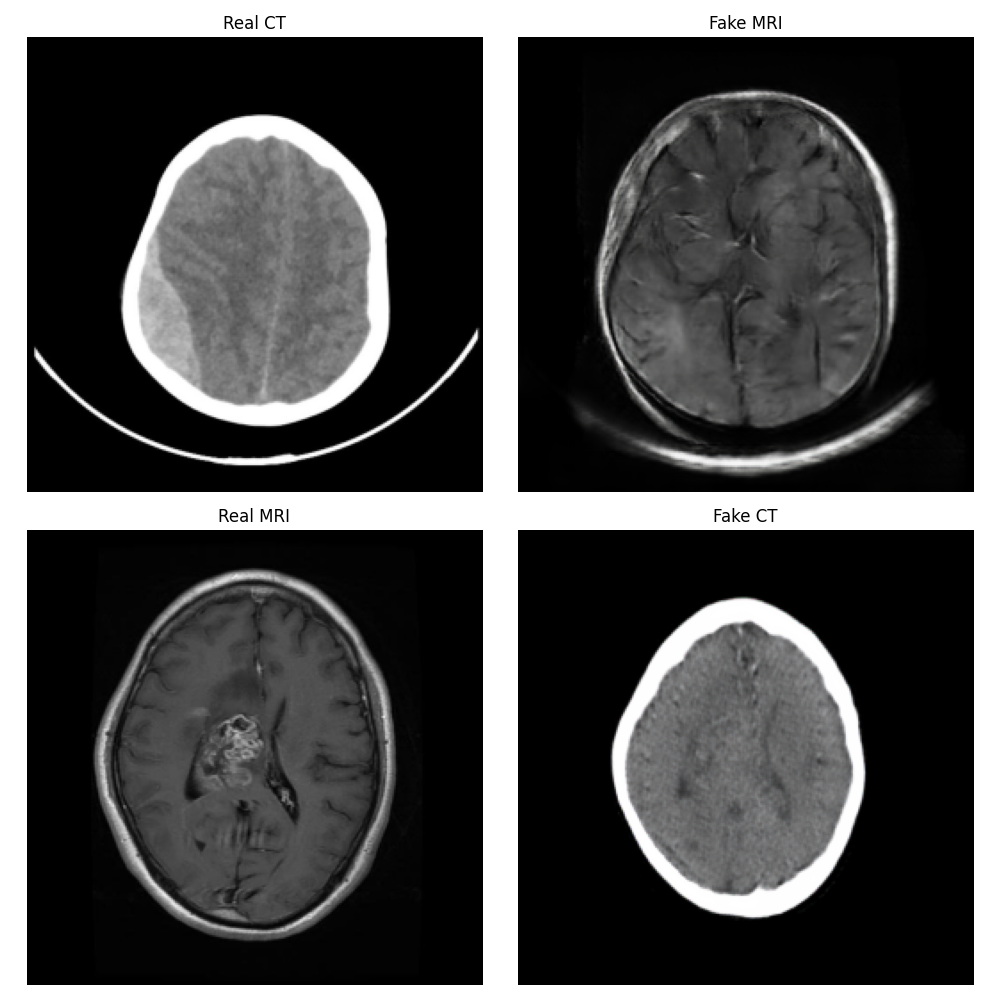
Epoch 4
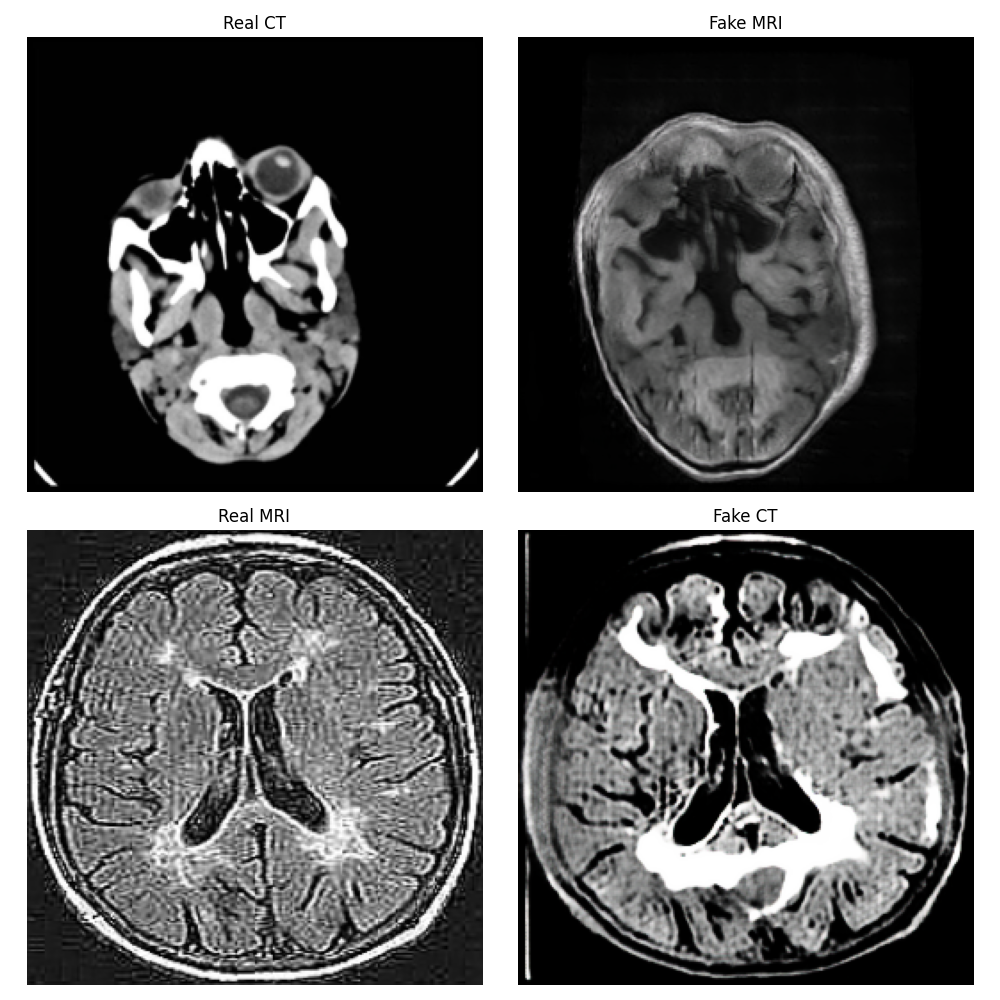
Epoch 5
Hyperparameters
Training Parameters
- Epochs: 40+
- Batch Size: 1
- Learning Rate: 0.0001
- Weight Decay: 6e-8
Model Parameters
- Latent Dimension: 256
- Filters: 16 (base)
- Kernel Size: 3x3
- Image Shape: 256x256x3
Performance Metrics
Quantitative Metrics
- PSNR: 32.4 dB
- SSIM: 0.91
- FID Score: 18.7
Training Metrics
- Generator Loss: ~1.5 (final)
- Discriminator Loss: ~0.6 (final)
- Cycle Consistency Loss: ~0.2